Six pillars.
One app.
No compromises.
Each of these would ship as a standalone product. In Workbench, they share state, context, and models — making each one exponentially more useful than it would be alone.
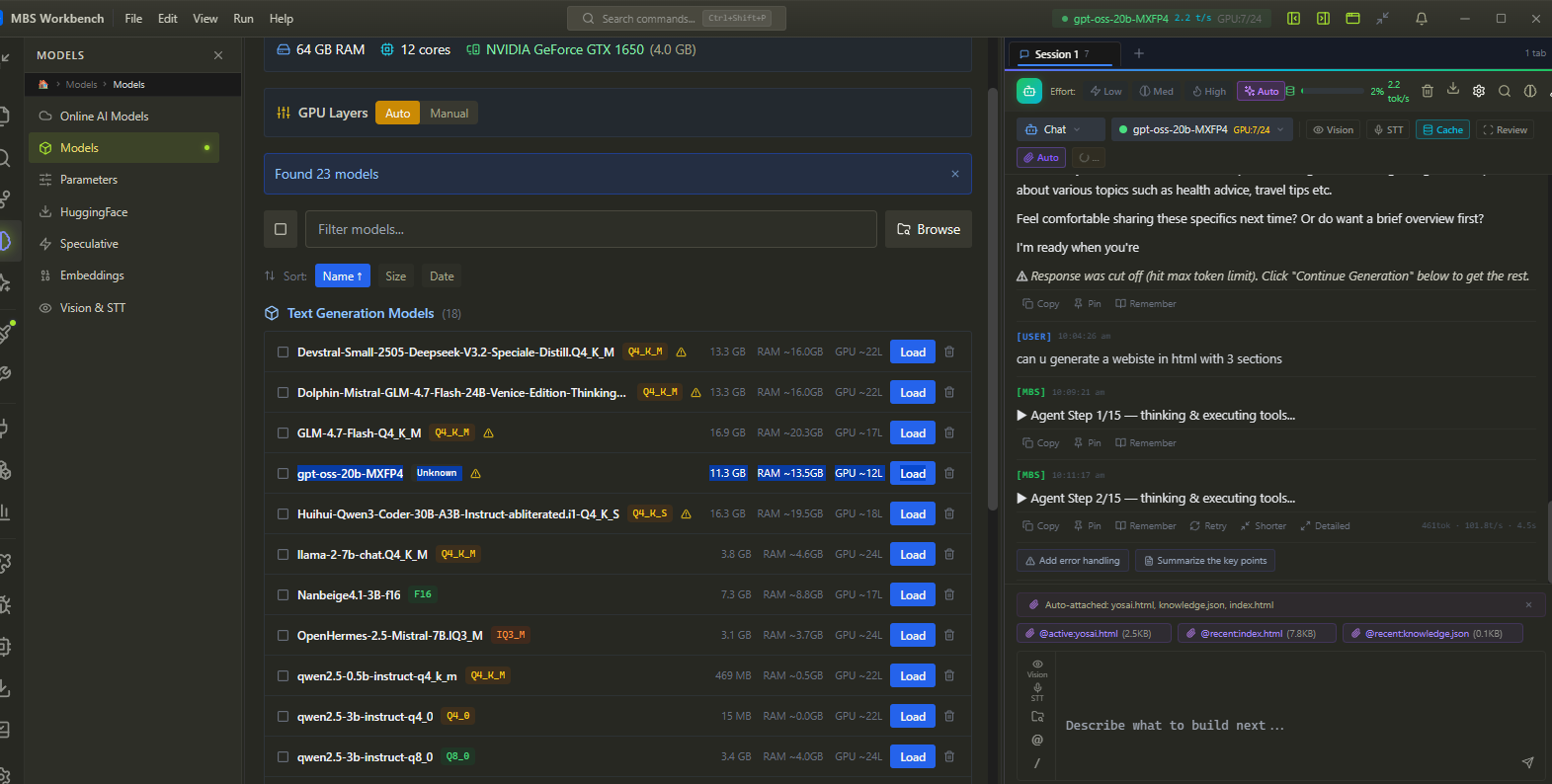
Local AI Engine — CUDA-accelerated. Zero cloud.
GGUF inference with Flash Attention v3 and speculative decoding. Any model, any size. Auto-configured on first launch — no CUDA setup, no quantization guesswork. Mix local and cloud in the same session.
mbsd daemon (JSON-RPC 2.0, TCP:3031) + TS & Python SDKs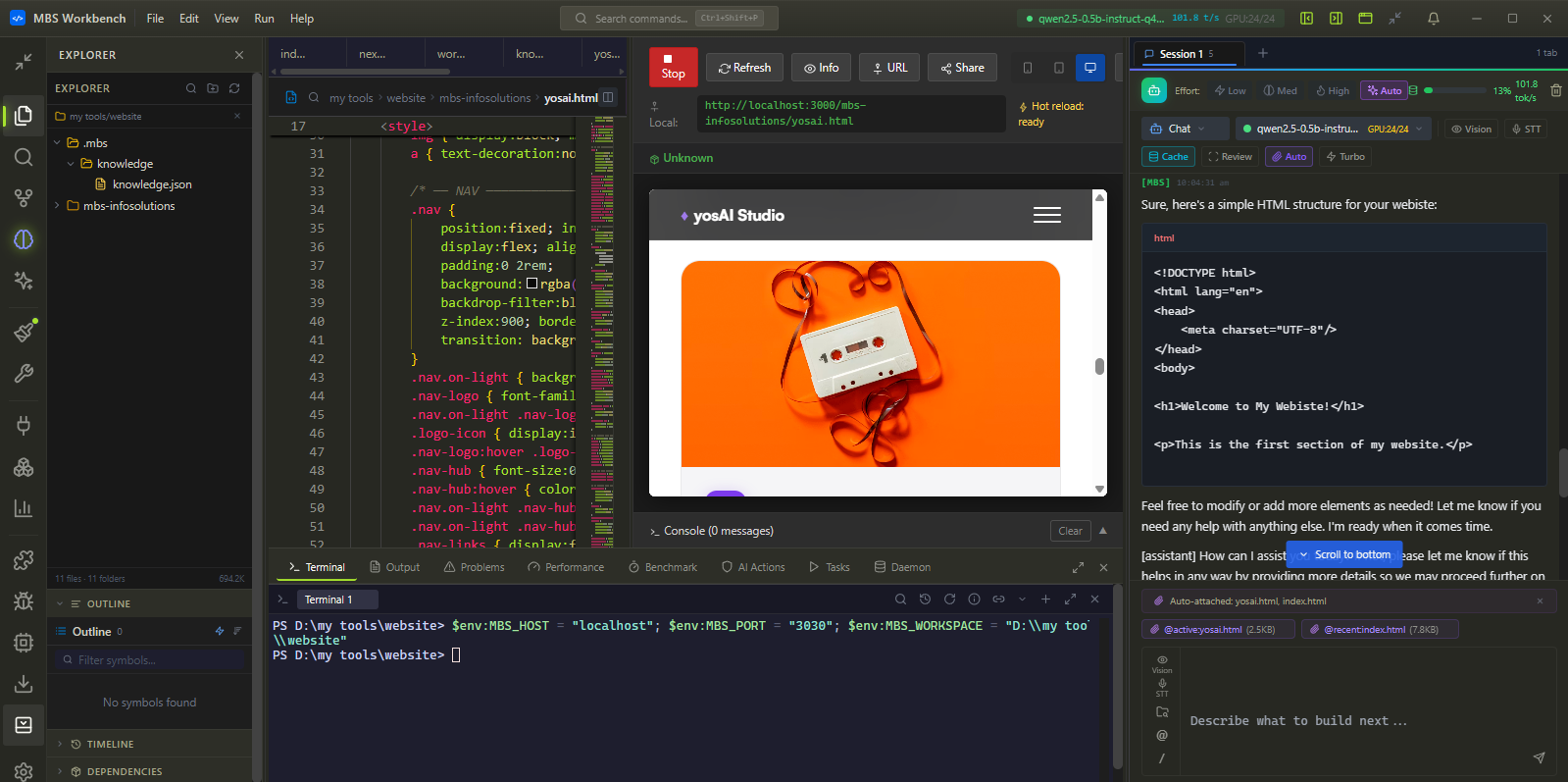
Professional Code Editor — real IDE, not a text field.
Monaco editor with full LSP, real PTY terminal, DAP debugger, and native Git. Every AI completion uses the local model in Pillar 1 — no additional API call, no latency, no context switch.
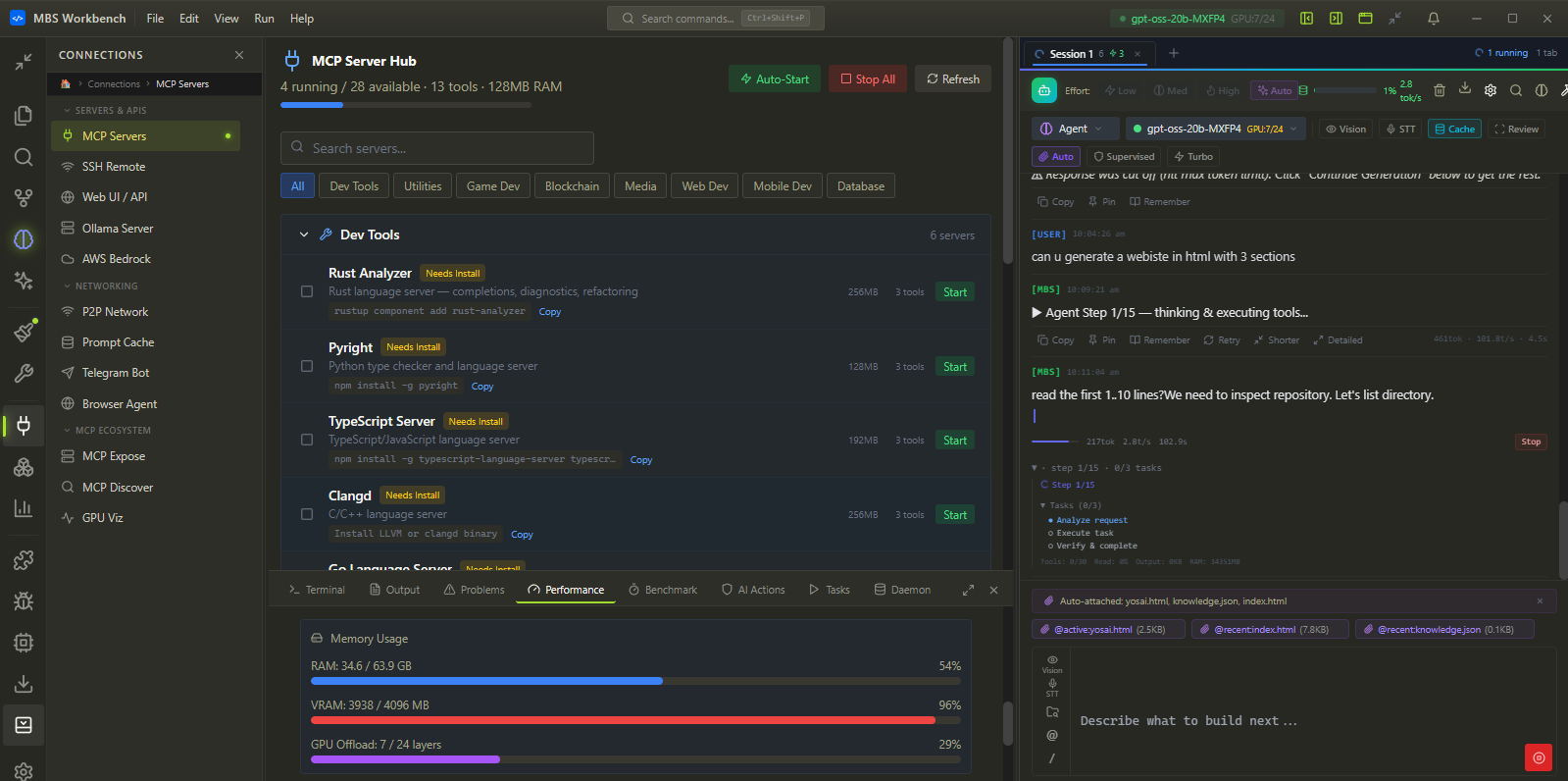
Autonomous Agents — goal to production, unattended.
Describe a goal. The agent decomposes it, edits files across your codebase, runs terminal commands, calls APIs, tests results, iterates — live audit trail every step. Safety gates prevent anything destructive without your approval.
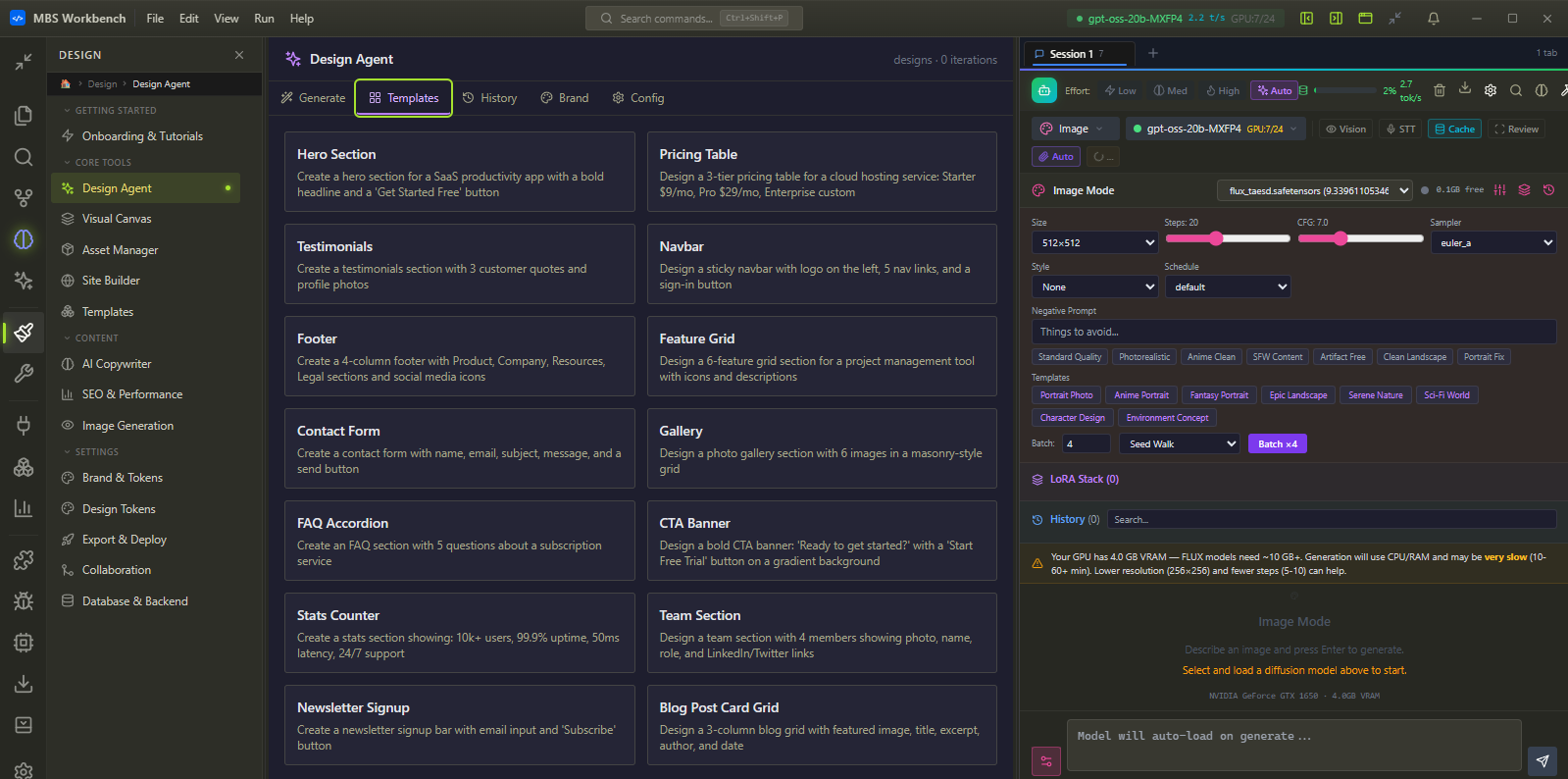
Creative Studio — images and voice, fully offline.
Complete Stable Diffusion pipeline and a professional Voice Studio — on your GPU, with no per-image cost, no API keys, no prompts shared anywhere. Generate until you’re satisfied.
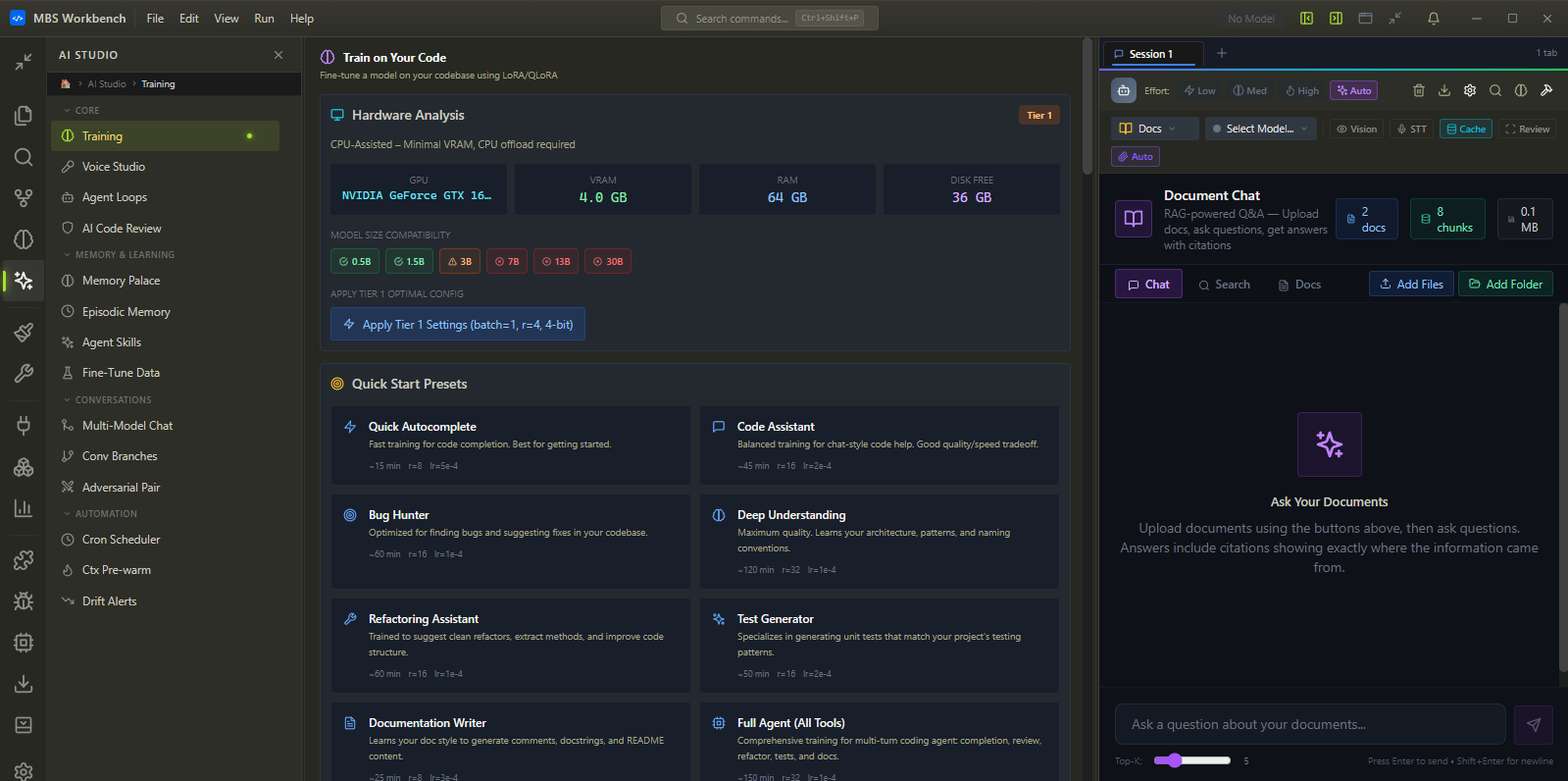
Model Training — fine-tune and use, without leaving the IDE.
Fine-tune any model on your own data. Watch it train. Export and load it directly into the inference engine. Cloud GPU rental is one click away when local hardware is not enough.
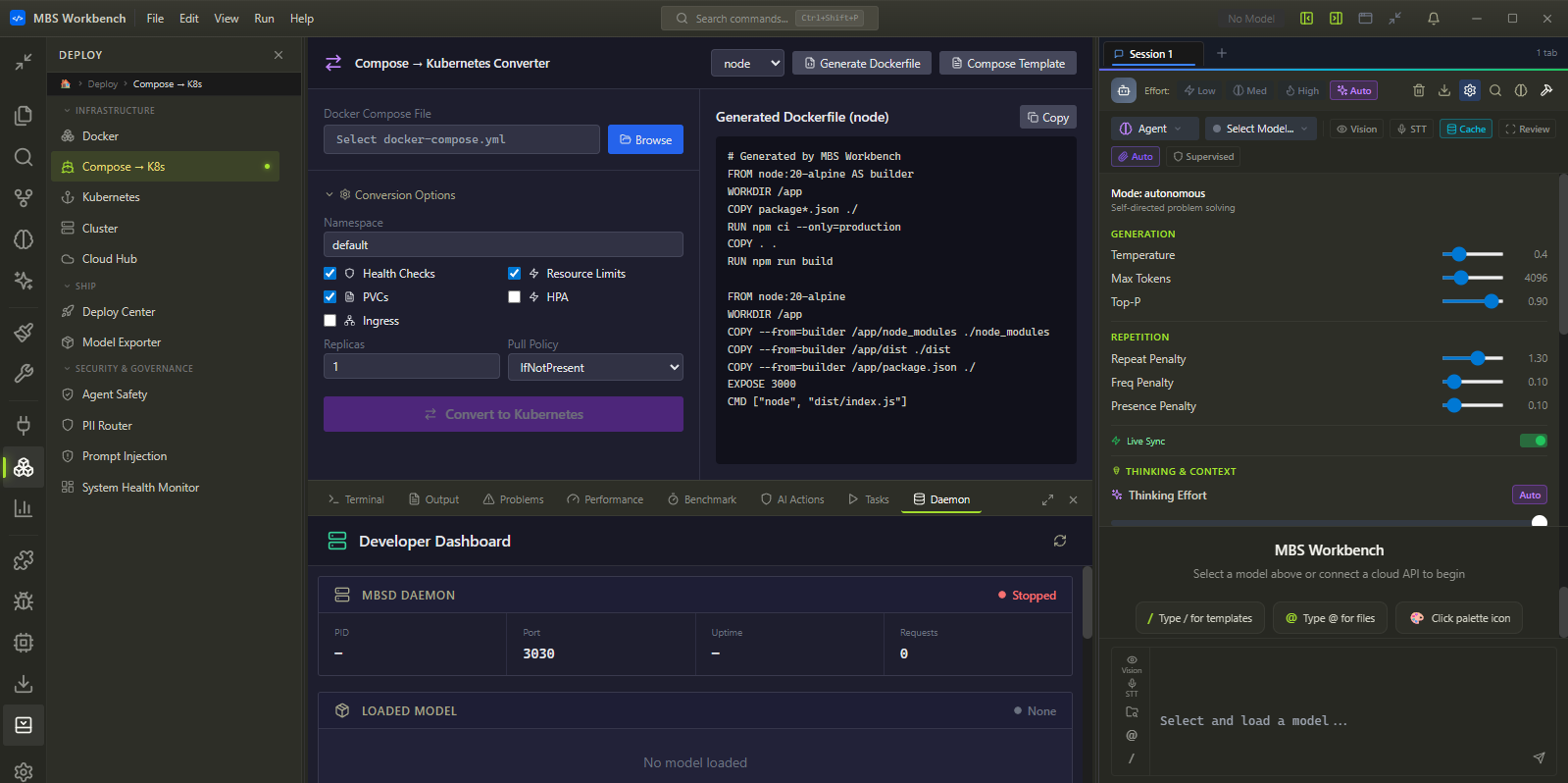
Deploy Anywhere — from the same window where you built it.
Every project built in Workbench ships to production without switching tools. Docker, Kubernetes, and 10 cloud providers in one panel. Cost estimates shown before you commit.
mbsd + mbs CLI + TS & Python SDKs for pipeline automation